Prelude:
What makes movies good or bad? Is it our emotional response towards them? Is it the critical reviews or the scores? Is it the association of popular directors or actors? Is it the amount they gross at the box office? What is it really that describes their success or failure? I have pondered over such questions many a times but never really got around to acknowledge them. Thus, when this project came along, I used it as an opportunity to try to find some answers this time around.
Understanding movies through data, as the name suggests, was an endeavour towards performing exploratory data analyis on a movie related dataset. My intentions behind this exploration were to simply study a dataset that could provide some insight into movies, its audiences and to an extent its commerce. In search of a dataset I turned to www.kaggle.com where I stumbled upon one that nicely fitted my needs. This fantastic dataset was created by chuansun76. It contained data from 5043 movies spread across 28 features scraped from www.imdb.com. Using this dataset as a base of my study I began my quest to understand movies through data.
Below is a complete list of features found in the dataset and here is a link for reference:- movie_title: Contains title of a movie
- color: Specifies whether a movie is black and white or color
- num_critic_for_reviews: Contains number of critic reviews per movie
- movie_facebook_likes: Contains number of facebook likes per movie
- duration: Contains duration of a movie in minutes
- director_name: Contains name of the director of a movie
- director_facebook_likes: Contains number of facebook likes for a director
- actor_3_name: Contains the name of the 3rd leading actor of a movie
- actor_3_facebook_likes: Contains number of facebook likes for actor 3
- actor_2_name: Contains name of 2nd leading actor of a movie
- actor_2_facebook_likes: Contains number of facebook likes for actor 2
- actor_1_name: Contains name of the actor in lead role
- actor_1_facebook_likes: Contains number of facebook likes for actor 1
- gross: Contains the amount a movie grossed in USD
- genres: Contains the sub-genres to which a movie belongs
- num_voted_users: Contains number of users votes for a movie
- cast_total_facebook_likes: Contains number of facebook likes for the entire cast of a movie
- facenumber_in_poster: Contains number of actor’s faces on a movie poster
- plot_keywords: Contains key plot words associated with a movie
- movie_imdb_link: Contains the link to the imdb movie page
- num_user_for_reviews: Contains the number of user generated reviews per movie
- language: Contains the language of a movie
- country: Contains the name of the country in which a movie was made
- content_rating: Contains maturity rating of a movie
- budget: Contains the amount of money spent in production per movie (not always in USD)
- title_year: Contains the year in which a film was released
- imdb_score: Contains user generated rating per movie
- aspect_ratio: Contains the size of the aspect ratio of a movie
Purpose:
The objective of this study was to attempt to observe general movie trends by examing factors like movie genres, user rating, production costs or box office earnings. So I focused primarily on three main features that could allow to me do so. I began the analysis by examining movies through genres, gradually shifting focus to year of release and finally to commercial failure or success. My idea was not to provide a comprehensive analysis rather to simply experiment with the dataset and discover things as I went along.
Setup:
Movies are chiefly categorised into 17 main genres: Action, Adventure, Fantasy, Comedy, Crime, Drama, Mystery, Romance, Horror, Thriller, Sci-Fi, Epics, Musical, Western, Animation, Biography and Documentary. IMDB however, categorises movies into sub genres. To be precise, the dataset contained 914 sub genres. Examining such vastly diverse set of data points individually would have taken forever. Hence, I decided I should simplify the domain of my study.
My first response towards simplifying the area of my research was to tidy the data. I Removed duplicates, blank items and NA values which reduced the data to 3739 observations out of the 5043 observation that were originally there. The second decision was to engineer new features from the available feature set in the data.
I created a new feature named ‘sub_genres’ to which I assigned all the values of the feature ‘genres’. I nullified ‘genres’ and then assigned new values to it. These values where the first word extracted from ‘sub_genres’. For example, if the sub genre is ‘Action|Crime| Thriller’, the first word ‘Action’ was the genre of the film.
Other features that were created were explained as and when they were used during the course of this project.
# remove duplicates if any
mdata <- mdata[!duplicated(mdata), ]
# removing na values
mdata <- na.omit(mdata)
# removing blank fields
mdata <- mdata[which(!(mdata$director_name == "" | mdata$color == "" | mdata$language == "" | mdata$content_rating == ""
| mdata$plot_keywords == "")),]
# fixing movie names
mdata$imdb_score <- gsub("Â", "", mdata$imdb_score)
# extracting genres from sub genres
mdata$sub_genres <- mdata$genres
mdata$genres <- NULL
mdata$genres <- factor(str_extract(mdata$sub_genres, pattern = "^[a-zA-Z]*"))
# creating a new feature called total_facebook_likes
mdata$total_facebook_likes <- mdata$director_facebook_likes +
mdata$actor_3_facebook_likes + mdata$actor_1_facebook_likes +
mdata$cast_total_facebook_likes + mdata$actor_2_facebook_likes
# converting imdb_score to numeric feature
mdata$imdb_score <- as.numeric(mdata$imdb_score)
# creating feature return_on_investment
mdata$budget <- mdata$budget/1000000
mdata$gross <- mdata$gross/1000000
mdata$return_on_investment <- (mdata$gross - mdata$budget)/mdata$budget
mdata$profit_loss <- ifelse(mdata$return_on_investment > 0, 1, 0) After tidying and updating the dataset this was how the new feature set looked like:
## 3723 Items
## 32 Fields## Updated feature set:## $factor
## [1] "color" "director_name" "actor_2_name"
## [4] "actor_1_name" "movie_title" "actor_3_name"
## [7] "plot_keywords" "movie_imdb_link" "language"
## [10] "country" "content_rating" "sub_genres"
## [13] "genres"
##
## $integer
## [1] "num_critic_for_reviews" "duration"
## [3] "director_facebook_likes" "actor_3_facebook_likes"
## [5] "actor_1_facebook_likes" "num_voted_users"
## [7] "cast_total_facebook_likes" "facenumber_in_poster"
## [9] "num_user_for_reviews" "title_year"
## [11] "actor_2_facebook_likes" "movie_facebook_likes"
## [13] "total_facebook_likes"
##
## $numeric
## [1] "gross" "budget" "imdb_score"
## [4] "aspect_ratio" "return_on_investment" "profit_loss"Structure:
## 'data.frame': 3723 obs. of 32 variables:
## $ color : Factor w/ 3 levels ""," Black and White",..: 3 3 3 3 3 3 3 3 3 3 ...
## $ director_name : Factor w/ 2399 levels "","A. Raven Cruz",..: 927 801 2027 377 106 2030 1652 1228 551 2394 ...
## $ num_critic_for_reviews : int 723 302 602 813 462 392 324 635 375 673 ...
## $ duration : int 178 169 148 164 132 156 100 141 153 183 ...
## $ director_facebook_likes : int 0 563 0 22000 475 0 15 0 282 0 ...
## $ actor_3_facebook_likes : int 855 1000 161 23000 530 4000 284 19000 10000 2000 ...
## $ actor_2_name : Factor w/ 3033 levels "","50 Cent","A. Michael Baldwin",..: 1407 2218 2488 534 2549 1227 801 2439 653 1703 ...
## $ actor_1_facebook_likes : int 1000 40000 11000 27000 640 24000 799 26000 25000 15000 ...
## $ gross : num 760.5 309.4 200.1 448.1 73.1 ...
## $ actor_1_name : Factor w/ 2098 levels "","50 Cent","A.J. Buckley",..: 302 979 353 1968 440 785 221 336 32 739 ...
## $ movie_title : Factor w/ 4917 levels "[Rec] ","[Rec] 2 ",..: 398 2731 3279 3708 1961 3291 3459 399 1631 462 ...
## $ num_voted_users : int 886204 471220 275868 1144337 212204 383056 294810 462669 321795 371639 ...
## $ cast_total_facebook_likes: int 4834 48350 11700 106759 1873 46055 2036 92000 58753 24450 ...
## $ actor_3_name : Factor w/ 3522 levels "","50 Cent","A.J. Buckley",..: 3442 1392 3134 1769 2714 1969 2162 3018 2941 55 ...
## $ facenumber_in_poster : int 0 0 1 0 1 0 1 4 3 0 ...
## $ plot_keywords : Factor w/ 4761 levels "","10 year old|dog|florida|girl|supermarket",..: 1320 4283 2076 3484 651 4745 29 1142 2005 1564 ...
## $ movie_imdb_link : Factor w/ 4919 levels "http://www.imdb.com/title/tt0006864/?ref_=fn_tt_tt_1",..: 2965 2721 4533 3756 2476 2526 2458 4546 2551 4690 ...
## $ num_user_for_reviews : int 3054 1238 994 2701 738 1902 387 1117 973 3018 ...
## $ language : Factor w/ 48 levels "","Aboriginal",..: 13 13 13 13 13 13 13 13 13 13 ...
## $ country : Factor w/ 66 levels "","Afghanistan",..: 65 65 63 65 65 65 65 65 63 65 ...
## $ content_rating : Factor w/ 19 levels "","Approved",..: 10 10 10 10 10 10 9 10 9 10 ...
## $ budget : num 237 300 245 250 264 ...
## $ title_year : int 2009 2007 2015 2012 2012 2007 2010 2015 2009 2016 ...
## $ actor_2_facebook_likes : int 936 5000 393 23000 632 11000 553 21000 11000 4000 ...
## $ imdb_score : num 7.9 7.1 6.8 8.5 6.6 6.2 7.8 7.5 7.5 6.9 ...
## $ aspect_ratio : num 1.78 2.35 2.35 2.35 2.35 2.35 1.85 2.35 2.35 2.35 ...
## $ movie_facebook_likes : int 33000 0 85000 164000 24000 0 29000 118000 10000 197000 ...
## $ sub_genres : Factor w/ 914 levels "Action","Action|Adventure",..: 107 101 128 288 126 120 308 126 447 126 ...
## $ genres : Factor w/ 17 levels "Action","Adventure",..: 1 1 1 1 1 1 2 1 2 1 ...
## $ total_facebook_likes : int 7625 94913 23254 201759 4150 85055 3687 158000 105035 45450 ...
## $ return_on_investment : num 2.2089 0.0313 -0.1834 0.7925 -0.7229 ...
## $ profit_loss : num 1 1 0 1 0 1 0 1 1 1 ...
## - attr(*, "na.action")=Class 'omit' Named int [1:1230] 5 56 85 99 100 177 198 204 240 246 ...
## .. ..- attr(*, "names")= chr [1:1230] "5" "56" "85" "99" ...Sample Data:
I set up some custom plot functions and plot styles for later use.
# setting up plotly label, axis and text customizations
f1 <- list(
family = "Old Standard TT, serif",
size = 14,
color = "grey"
)
f2 <- list(
family = "Old Standard TT, serif",
size = 10,
color = "black"
)
a <- list(
titlefont = f1,
showticklabels = T,
tickangle = -45,
tickfont = f2
)
m <- list(
l = 50,
r = 50,
b = 100,
t = 100,
pad = 4
)
# annotations for subplot
a1 <- list(x = 0.5, y = 1.0,
showarrow = FALSE,
text = "Distribution of bugdet",
xanchor = "center",
xref = "paper",
yanchor = "bottom",
yref = "paper",
font = f1)
b1 <- list(x = 0.5, y = 1.0,
showarrow = FALSE,
text = "Distribution of gross",
xanchor = "center",
xref = "paper",
yanchor = "bottom",
yref = "paper",
font = f1)
# creating a function called scatter_plot for
# plotting scatter plots using ggplot and plotly
scatter_plot <- function(x, y, xlabel, ylabel, title,
text1, text2, text3,
alpha = NULL){
if(is.null(alpha)) alpha <- 0.4
gp <- ggplot(data = mdata, mapping = aes(x = x, y = y,
text = paste(text1, x,
text2, y,
text3, movie_title)))
plot <- gp + geom_point(position = "jitter",
show.legend = F, shape = 21,
stroke = .2, alpha = alpha) +
xlab(xlabel) +
ylab(ylabel) +
ggtitle(title) +
theme_minimal() +
theme(legend.position = "none",
plot.title = element_text(size = 12, face = "bold",
family = "Times",
color = "darkgrey"))
ggplotly(plot, tooltip = "text") %>%
layout(m, xaxis = a, yaxis = a)
}
# creating function for plotting scatter plot using facet wrap
facet_plot <- function(x, y, xlabel, ylabel, alpha = NULL){
if(is.null(alpha)) alpha <- 1
fp <- ggplot(data = mdata, mapping = aes(x = x, y = y))
fp + geom_point(aes(fill = genres), position = "jitter",
show.legend = F, shape = 21,
stroke = 0.2, alpha = alpha) +
xlab(xlabel) +
ylab(ylabel) +
facet_wrap(~genres, scales = "free") +
theme_minimal()
}
# creating a function for plotting a simple histogram
hist_plot <- function(x, xlabel, bwidth, fill = NULL, color = NULL){
if(is.null(fill)) fill <- "orange"
if(is.null(color)) color <- "black"
hp <- ggplot(data = mdata, mapping = aes(x = x))
gp <- hp + geom_histogram(binwidth = bwidth, fill = fill,
color = color,
size = 0.2,
alpha = 0.7,
show.legend = F) +
xlab(xlabel) +
theme_minimal()
ggplotly(gp) %>%
layout(margin = m, xaxis = a, yaxis = a)
}
# creating a function for plotting histogram using facet wrap
facet_hist_plot <- function(x, xlabel, bwidth){
hp <- ggplot(data = mdata, mapping = aes(x = x))
hp + geom_histogram(aes(fill = genres), binwidth = bwidth,
show.legend = F,
color = "black", size = 0.2,
alpha = 0.8) +
xlab(xlabel) +
theme_minimal() +
theme(legend.position = "none",
axis.text = element_text(size = 12, angle = 20),
axis.title = element_text(size = 14,
family = "Times",
color = "darkgrey",
face = "bold")) +
facet_wrap(~ genres, scales = "free_y", ncol = 4)
}
# creating function for plotting histograms for budget and gross
budg_gross_hist <- function(x){
bh <- ggplot(mdata, aes(x = x))
bh + geom_histogram(binwidth = 0.05,
fill = sample(brewer.pal(11, "Spectral"), 1),
color = "black",
size = 0.09,
alpha = 0.7) +
scale_x_log10() +
theme_minimal()
ggplotly() %>%
layout(m, xaxis = a, yaxis = a)
}
# creating a function for ploting bar graphs
bar_plot <- function(data, x, y, info, xlabl, ylabl, title,
deci = NULL, suf = NULL){
if(is.null(suf)) suf <- ""
if(is.null(deci)) deci <- 0
b1 <- ggplot(data, aes(x = reorder(genres, x),
y = y,
text = paste("Genre:", genres,
info,
round(y, deci), suf)))
b1 + geom_bar(aes(fill = genres), stat = "identity",
show.legend = F, color = "black", size = 0.2,
width = 0.7, alpha = 0.7) +
xlab(xlabl) +
ylab(ylabl) +
ggtitle(title) +
theme_minimal() +
theme(legend.position = "none",
plot.title = element_text(size = 14,
color = "grey", family = "Times")) +
scale_fill_brewer(palette = "Spectral")
ggplotly(tooltip = "text") %>%
layout(margin = m, xaxis = a, yaxis = a)
}
# creating a function for plotting plotly line graph for title_year
line_graph <- function(data, y, name){
scat_p1 <- plot_ly(data, x = ~title_year, y = ~ y,
name = name, type = 'scatter', mode = 'lines',
line = list(color = sample(brewer.pal(11, "Spectral"), 1))) %>%
layout(xaxis = list(title = "Title Year", zeroline = F,
showline = F,
showticklabels = T),
yaxis = list(title = "Average Score"),
title = "Line Graph for Avg Score/Avg Votes/Avg User Review by Title Year",
font = list(family = "Serif", color = "grey"),
legend = list(orientation = "h", size = 6,
bgcolor = "#E2E2E2",
bordercolor = "darkgrey",
borderwidth = 1),
margin = m)
scat_p1
}Act 1: Early Exploration
With this much simplified form of the data now available, I began asking some direct questions. One of the first things I wanted to know was Which genre did most movies belonged to? I thought an interactive donut chart would be a good way to visualize the count of movies per genre. I used the plotly library to make this work.
Out of the 17 available genres in the dataset, Comedy topped the list with 26.7% share of movies falling in this category. Not too far behind with 25.8% share was Action. In the third spot was Drama with 17.9% share followed by Adventure with 9.93%, Crime with 6.87%, Biography with 5.54% and Horror with 4.32%. The last 3 genres Animation, Fantasy and Documentary each had less than 50 movies in their share. Mystery, Sci, Romance, Western, Thriller, Musical and Family genres were excluded from this count because they contained too few films.
The next question I had in mind was Which were the top rated genres? Rating here can be expressed as a viewer’s likeness towards a film, measured on a scale of 1 to 10. 1 being the lowest while 10 being the highest rating. I thought looking at the distribution of imdb scores would be a good way to start this investigation.
The distribution looked normal at first sight. However, more scores between 6.0 to 7.0 were skewing it slightly to the left. 6.7 was the most frequent score in the distribution observed 175 times. Taking a summary of imdb scores revealed that scores ranged between a minimum of 1.6 to a maximum of 9.3. The first quartile score was 5.9 and third quartile was 7.2. The mean imdb score was 6.5. Median score was 6.6.
The next graph I plotted was a genre wise distribution of scores.
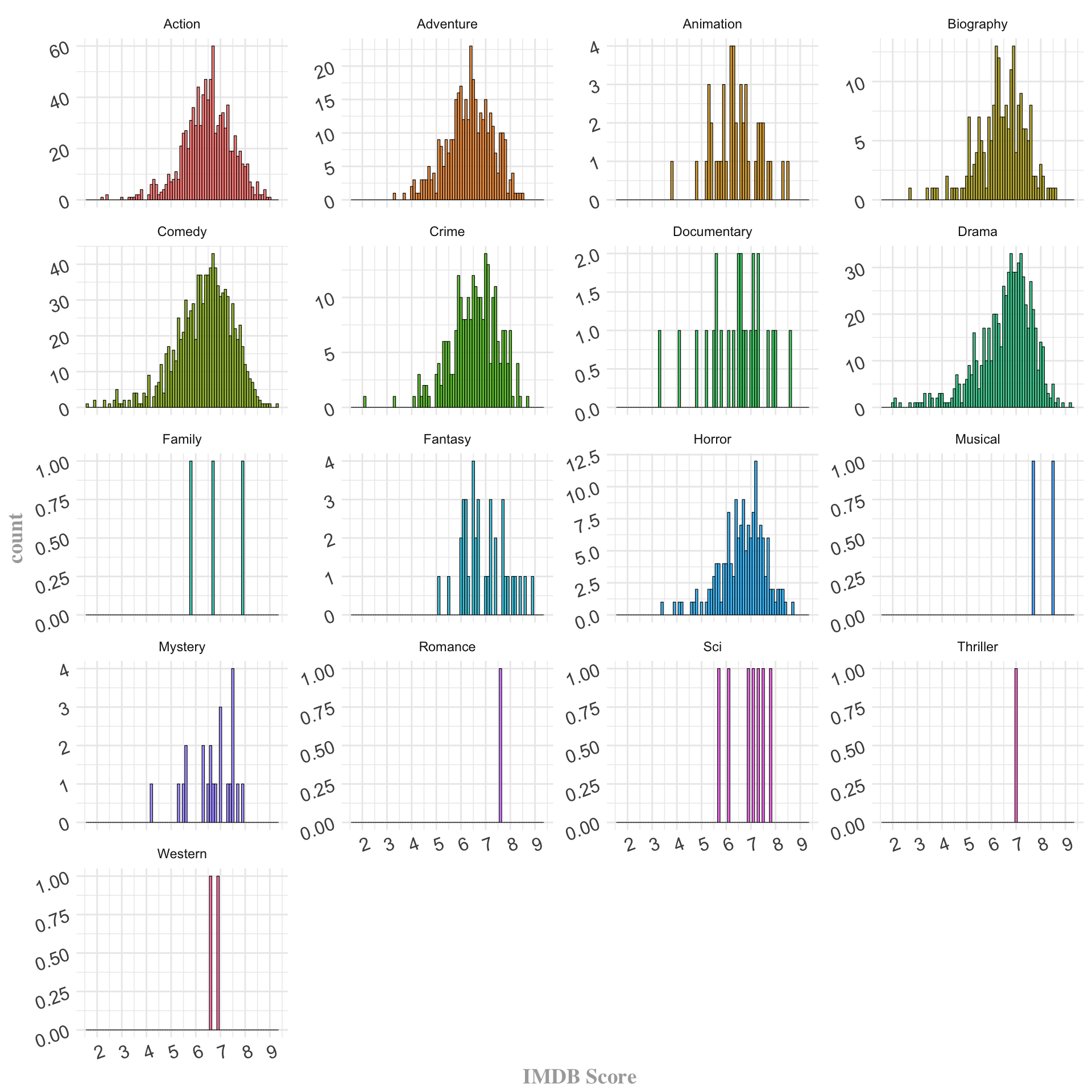
The plot gave a pretty good view of how the scores were distributed across each individual genre. In general, all the distributions were skewing slightly to the left. But a few genres were skewed a tad bit more towards the left than others. For example, Action movies seemed to have a slighlty lesser skew compared to Drama or Biography. Checking the genre wise score summary indeed revealed that Action movies had a lower mean score compared to other two genres. This prompted me to compare distributions of these three genres seperately just to have a closer look at how they faired against each other.
As expected, the frequency plot made it clear that Action had the least amount of skew compared to Drama and Biography. This was a good time I thought, to compare all the genres against each other. I grouped the data by genres and using the feature imdb_score I computed average ratings of each genre. I then, plotted a bar chart to display the top ten genres based on those averages.
All the genres had an average rating of 6.2 and above and were competitively rated against each other. Biography, with an average rating of 7.2, came out as the highest rated genre. Comedy, with an average score of 6.2, was the least rated genre of all. However, genre ratings alone did not imply much, user votes also needed to be taken into consideration.
So the next thing I asked was, Which were the most voted genres? By grouping genres together and using the feature num_voted_users I was able to compute average number of votes for each genre. Based on these averages I graphed the top ten results using a bar chart.
With 188682 average votes per movie, Mystery was the most voted genre. Action, having 30% lesser votes than Mystery, was in the second place. Besides being the least rated, Comedy was the least voted genre of as well. Documentary did not even make the list despite having an average rating of 6.8. Maybe there weren’t very many documentary movies fans on imdb but those who were, rated them relatively well.
Which were the most facebook liked genres? was my next question. In the setup phase of the analysis, I had created a feature named total_facebook_likes by summing up other features like: director_facebook_likes, actor_1_facebook_likes, actor_2_facebook_likes, actor_3_facebook_likes, cast_total_facebook_likes. It was created specifically to answer such kind of questions. Using this feature, I was able to compute average facebook likes on a genre wise basis. Based on those averages, I plotted the ten most most fb liked genres.
Biography was the most liked genre with average likes of 28416 likes per movie. Fantasy was the least liked genre with 13340 facebook likes per movie.
The next thing I was curious about was On which genres did producers invest more? My technique to answer this question remained the same, baring one exception. Before grouping the genres together, I filtered out budget and gross values that existed outide their respective inter quartile ranges. Almost 20% of budget and gross values were in currencies other than USD which created some awfully extreme observations. By filtering out such extreme values I thought I was able to normalise the data to an extent.
The subplot below displays log transformed histograms for Distribution of budget and gross.
After filtering out extreme values, I used the budget feature to compute average budget of each genre. On the basis of those averages I plotted a bar chart of the ten most budgeted genres.
Action flicks were the most costly to produce having a whopping 35 Million dollars average budget per film. Adventure flicks with an average budget of 30.38 Million dollars per film took the second place. Animation took a close third spot with almost the same budget as Adventure. Fantasy had the lowest budget per film of 19.3 Million dollars.
After having known how much on an average was spent on producing a movie, the next obvious thing to know was how much does a movie pay back. In other words, Which were the most porfitable genres? Profit in this case was calculated by substracting budget from gross. Then the mean gross profit was calculated on a genre wise basis. \[ gross\,profit \,=\, gross\, - \, budget\]
I was surprised to see Fantasy being the most profitable genre of all. Fantasy movies were cheapest to produce yet yielded the maximum amount of profit per film. Adventure came in second with an average profit of 20 Million. Horror was at the third spot despite having a lower budget per film than most genres. Crime was the least profitable genre, making an average gross profit of 6.24 Million dollars per movie.
Examining the genre wise budget and profit figures almost instantly sparked another question, Which genres gave the best return on investment? It wasn’t directly possible to compute ROI because there was no ROI feature available. However, after creating a feature called return_on_investement I was able to do so. Using this feature, I calculated an average ROI on a genre wise basis and plotted the ten most investment efficient genres based on those averages.
Here is the formula for calculating ROI: \[ROI\, = {\,gross\,-\,budget \above 1pt budget}\]
Fantasy, as expected, had the highest return on investment. Horror had the second highest return on investment. Adventure came in third while Animation was the least investment efficient genre. These observations immediately triggered another question. Which genres had higher rate of commercial success?
Before diving in to answer this question, I thought knowing about how many movies in total made profit or loss would be a nice. A donut chart helped me with that.
46.3% movies made loss while 53.7% movies made profit.
Higher number of profitable movies within a genre meant that it had a higher rate of monetery success. Therefore, to correctly calculate rate of success, I created a feature called profit_loss containing binary values. For all values where ROI was greater than zero, profit_loss was assigned a value of 1, else it was assinged a value of 0. Through this feature, I was able to extract a subset of all profitable movies and then was able to compute their percentages on a genre wise basis. Finally I plotted a bar chart to display the ten most commercially successful genres.
Fantasy took the top spot having an incredible 78.38% rate of commercial success. A very close second was Horror with 75.47% rate of commercial success. Documentary, surpisingly, was third with a decent succes rate of 61.54%. Drama, Action Biography all had a success rate less than 50%.
Did profitable movies recieve more appreciation by the users? I plotted a frequency plot to examine the frequency of scores separated by profit or loss making movies. This gave me a pretty good ides of how users rated both profit or loss making movies.
There was surely something going on! The distrubtion for profit, labeled 1, was clearly more left skewed than the distribution for loss. Checking out their summaries confirmed that profit making movies had a better distribution of scores than loss making movies in every way. It was safe to assume that movies fairing well at box office had a higher chance of being appreciated by the audiences.
## factor(mdata$profit_loss): 0
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1.900 5.700 6.350 6.245 7.000 8.800
## --------------------------------------------------------
## factor(mdata$profit_loss): 1
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1.600 6.100 6.700 6.656 7.400 9.300Which were the top rated movies? I used the same bar chart approach again to answer this question. However, this time my intentions where to provide more information through the plot. I used this plot not only to display names of ten best rated films but also display information like genre name, director name, title year, budget, lead actor for each of those films. By hovering the mouse cursor over the bars of the plot I was able to view this information. This led to some interesting observations.
The interesting bit about this plot was the fact that most films in the plot were released before the year 2000 and yet were rated highly. For example, Alfred Hitchcock’s 1960s film Psycho, not only had an astonishing ROI of 38.7 but also had an excellent rating of 8.5. Another 1960s film, Sergio Leone directed, The Good, the Bad and the Ugly had a rating of 8.9 and an ROI of 4.1. The late 1970s, Ridley Scott directed, Alien was another such example. The Shawshank Redemption released in 1994 was the highest rated movie of the entire dataset! I wasn’t sure what to think of it except thinking questions like: Were older films better than newer ones? Was there a pattern between older films getting higher ratings? I wasn’t sure because there were too few observations to make an any assumptions. I decided to investigate this further.
I created a new categorical feature named before_n_after_2000 containing binary values 0 and 1. Using the feature title_year, which contained release year corresponding to a title, I separated movies released before and after the year 2000. Movies released before the year 2000 were assigned a value of 0 else the value was 1. After having created this feature I used it to graph a distribution of imdb scores separated by 0 & 1 values.
The distributions alone couldn’t provide any conclusive evidence concerning older movies getting higher ratings. Checking the summary of scores did reveal that average rating of films released before 2000 was higher than the average rating of films released after 2000, but the difference was negligible. The only glaring difference between the two distribution was the count of movies in both categories. 2703 movies in the dataset were released after the year 2000 while only 1020 films were released before. A more thorough investigation was needed into this matter.
Section Overview
What was the structure of my dataset?
For my analysis I used a dataset containing movie data scraped from imdb.com. This dataset was created by chuansun76 and was downloaded from kaggle.com. The dataset and the information concerning it can be found here. Originally the dataset contained 5043 observations with 28 features. However, during the course my analysis the dataset was reduced to 3723 observations and the feature set was augmented to 33 features.
What were the main feature(s) of interest in my dataset?
Because this section focused on analysing movies through genres, the most intresting feature of my dataset was genre itself. ‘genres’ was basically a categorical feature in the dataset used for classifying movies. In its original form however, the feature wasn’t of much use to me. I had to modify it to make it work according to my needs. Using genres along with other features like budget, gross, return_on_investment, imdb_score, num_users_voted, total_facebook_likes and profit_loss I was able to explore different aspects of the data.
What other features in the dataset would help support my investigation into my feature(s) of interest?
One feature that I did not use during my analysis, which I thought could have revealed some interesting observations, was content_rating. This feature contained information regarding maturity ratings of a movie as set by Motion Picture Association of America (MPAA). I could have used this feature to explore maturity ratings of different genres. For example, I could have used it to examine which genre contained maximum number of R rated films. Then I could have used it further to explore highly rated or highly profitable R rated movies. I could have used this feature to create a new feature containing age groups corresponding to their maturity ratings.
As mentioned earlier, there were originally 28 variables in the dataset which were augmented to 33 by the end of this part of the analysis. Here is a list of those features I created along with their brief decriptions:
- sub_genres: A categorical feature created out of genres. All the items from genres were tranfered to this feature.
- genres: A categorical feature that originally existed in the dataset. It was modified to contain just the first word from sub_genres.
- total_facebook_likes: A quantitative feature created by summing all the ‘facebook_likes’ features in the dataset.
- return_on_investment: A quantitative feature created from features gross and budget ((gross - budget) / budget).
- profit_loss: A binary feature assigned value of 1 if ROI is greater than zero else assigned value of 0.
- before_n_after_2000: A binary feature assigned value of 1 if title_year is greater than or equal to year 2000 else its value is 0.
Act 2: Trends and Relationships
In this section of the project I focused on observing trends and relationships between some of the features that I had analysed previously. I introduced other features of interest apart from genres to support my investigation and further the progress of this project.
In the previous section of the project I had briefly introduced release year of movie titles into my investigation. I wanted to expand on that approach further in this section. Thus, I used title year in association with some other features of the dataset to examine some trends. The first question I asked in this regard was, Does release year of a movie affect its user rating, votes or reviews?
I wanted to observe how the values of ratings, votes and reviews changed together over the course of time. I was able to do so, by plotting line graphs of each of those variables and then subplotting them together.
The graph showed quite clearly that user ratings were declining with time. But such trends were not observed for user votes or user reviews. However, one interesting thing that was quite visible from the trends was that votes and reviews were peaking where the ratings were higher and dipping where they were lower. These were definite signs of correlation between the three variables.
Plot Highlights:- Average rating peaked at 8.9 for the year 1966.
- Average votes peaked at 586281 for the year 1972.
- Average user reviews peaked at 1210 for the year 1972 as well.
Does release year affect budget and gross? was the next question. To answer this question I used title year with variables budget and gross. This time, instead of plotting two separate line graphs for budget and gross and then subplotting them, I plotted both the features together in the same graph.
It was evident from the plot that both budget and gross trends were rising with time. This meant that the cost of producing movies had steadily increased over the years and so had the amount they grossed at the box office.
Plot Highlights:- Highest average budget was 104.97 MM dollars for year 2006
- Highest average gross was 184.93 MM dollars for year 1937
Was there a correlation between user votes and imdb score? A connection between user votes and imdb score was observed in the time series plot I had graphed earlier. This was a good time to investigate their relationship further and check how strong their bond was. I did that by plotting a scatter plot for user votes versus imdb score.
Because of over plotting it was difficult to observe correlations between user rating and votes for much of the data points. However, in general, the plot definitely showed a positive correlation between rating and votes. In other words, the observation suggested that users voted more for highly rated movies. This connection between rating and votes was further accentuated by the boxplot I plotted next.
# breaking num_users_voted into 4 buckets
mdata$vote_bucket <- cut(mdata$num_voted_users,
c(0, 50000, 100000, 300000, 500000))I broke votes into 4 buckets and assigned those values to a new feature called vote_buckets. Then I plotted boxplots for each of those buckets to show their range of scores. The constantly rising mean scores as the votes increased, was further evidence of the strong correlation between users votes and user rating.
After observing a connection between votes and rating I was curious to know, Was there a correlation between user votes and user reviews?
# creating a formattable showing average reviews per film
# values are color coded to show their linear increase as the number
# of votes increases
na.omit(mdata) %>%
group_by(vote_bucket) %>%
summarise(average_review_per_film =
round(mean(num_user_for_reviews))) %>%
formattable(list(average_review_per_film =
color_bar(sample(brewer.pal(11, "Spectral"),1)))) %>%
as.datatable()Surely there was! The plots showed quite an obvious positive correlation between user votes and user reviews. I subplotted the same scatter plot twice. One with normal view, on the left. Second with a more zoomed in view, on the right. As I zoomed in on the plot by filtering out values outside 5000 - 50000 on the x axis and 0 - 1000 on the y axis, the correlation got more pronounced.
To examine this realtionship further, I used a formattable table to show average reviews per film in each of the vote buckets I had created earlier. The color coded cells showed very simply the increase in number of reviews as the number of votes increased. In much simpler words, all this meant that films that were voted more were also reviewed more.
Do higher rated movies gross more? First, I plotted a scatter plot to see if there was connection between the two.
I couldn’t observe any apparent connection between the two variables. I thought, may be log transforming the score values could make their connection more visible. So I plotted the same scatter plot, this time with log transformed predictor values.
Despite transforming the values there wasn’t much to write home about. The summary line that I plotted along with the plot did, however, show that gross values were gradually rising with higher scores. But the correlation between ratings and gross was too weak. To be sure about this, I used the cor function to measure the correlation coefficient of the two variable.
# correlation between imdb_score and gross of the entire data
round(cor(mdata$imdb_score, mdata$gross, method = "pearson"),2)## [1] 0.22The r value of 0.22 was an indication that correlation between rating and gross wasn’t statistically meaningful. To test this relationship even further, I measured the correlation between rating and gross of only profit making movies.
# correlation between imdb_score and gross for profitable movies
prof <- mdata[mdata$profit_loss == 1,]
with(prof, round(cor(imdb_score, gross, method = "pearson"), 2))## [1] 0.22That too, came out to be statistically insignificant.
User ratings had failed to show any meaningful connection with gross, but what about user reviews? Did more reviewed movies make more money?
I plotted a scatter plot to find out.
Indeed, user reviews had a visibly higher positive relationship with gross than user rating. Their r value was measured to be 0.55, suggesting that their correlation was more than moderate.
# correlation between user reviews and gross
round(cor(mdata$num_user_for_reviews, mdata$gross),2)## [1] 0.55I broke user reviews into 4 buckets and assigned them to a new variable called review_bucket. Then I used a formattable table to show average gross per film in each of those review buckets. I color coded the cells to accentuate the increase in average gross as the reviews increased. These observations gave enough evidence to safely assume that movies that were reviewed more were more successful at the box office.
Section Overview
What were some of the relationships I observed in this part of the investigation? How did the feature(s) of interest vary with other features in the dataset?In this section I used features like title year, user votes, user reviews and user votes to establish correlations either with one another or with other variables in the dataset. Some noteworthy correlations that I observed during the course of this section are mentioned below:
- Using title year as a feature of interest, I investigated correlations between user ratings, user votes and user reviews. User rating, specifically, showed a negative correlation with title year. Meaning that user rating for movies had declined over a period of time. User votes and user reviews, however, did not show any significant trends with respect to title year.
- Features like budget and gross showed a positive relationship with title year. Their trends revealed that production costs and box office earnings had both increased with time.
- Strong positive correlations were observed for user rating, user votes and user reviews that led me to conclude that higher rated movies were more voted and more reviewed.
- A siginificantly positive correlation was observed between user reviews and gross suggesting that movies that were reviewed more earned more at the box office.
One of my favorite features in this section was title year. Using title year with other variables, I was able to observe changes in the values of those variable over a period of time. This was specifically helpful in observing trends related to user rating, budget and gross. In this respect title year was unlike any other feature I used in the dataset.
What was the strongest relationship I found?
The strongest relationship I observed in this section was between user votes and user reviews. They had a positive correlation suggesting, movies that were voted more were reviewed more as well. The scatter plot along with a formidable r value of 0.77 were able to display their correspondence quite convincingly.
Act 3: The Last Enquiry
In this section I focused on investigating data on the basis of gross profit or gross loss a film made. I was specifically interested in knowing how much profit or loss on an average did films make over a period of time (or in this case years). Using title_year, I was able to plot a bar chart for average gross profit/loss per year and separated those values by using another feature, profit_loss. Though the graph represented the values quite effectively, yet, I felt that the information wasn’t quite complete. I felt that I also needed to know the number of profit or loss making films per year. In other words, I needed to know what was the profit to loss ratio of movies per year. Once I had that plot in place, I subplotted the two plots and presented them together. There was just one more plot needed to conclude this investigation. A plot that could intuitively display the trends of profit to loss ratio over time. Using a line graph I was able to plot those trends accordingly.
With an average gross profit of 182.93 Million Dollars, the year 1937 was by far the best year for movies making money. On the other hand, 1988 seemed to be the worst year for the film industry observing an average gross loss close to 188 Million Dollars. Plotting the average gross profit/loss figures gave a good idea of how those values were spread across the years, but it was the profit to loss ratio of films that really showed me how more number of films were losing money over the year. One thing to note here was the absense of a lot of bar in the profit to loss ratio bar graph. That happened because some ratios remained undefined due to one of the values in the ratio being 0. However, even with those missing values, the graph was able to display the consistent decline in profit ratios from 1980 onwards quite clearly. The highest peak in the graph was observed for the year 1983 where the profit-loss ratio was a stupendous 12:1. These figures hit rock bottom by the year 2008 where the ratio was reduced to a meagre 0.76:1.
The table below conveys the story of the commercial side of cinema more elaborately.
The table clearly shows how more and more films started lose money from 1990 onwards. And then there was this patch between 2000 - 2012 where more than 50% films on an average were losing money. Nonetheless, total gross profit figures told a completely different story. Despite lesser films succeeding at the box office, the film industry was still making higher profits than loss. These observations were certainly favouring the film industry as a whole. But the falling success rate of films was not an encouraging sign for independent producers or filmmakers keen on establishing themselves in the industry.
There was just one final thing left to do, plot a yearly profit-loss ratio on a genre wise basis. Because I wanted genres with lesser undefined ratios, I used only those genres that contained a count of more than hundred movies.
All the genres showed different profit-loss ratio trends. But Action showed the most consistent decline in profit ratios than other genres. Below is a table that summarises the key points of the plot and more.
Overview
What were some of the relationships I observed in this part of the investigation. Were there features that strengthened each other in terms of looking at my feature(s) of interest?
This section gave me the opportunity to study the business aspect of movie making. I was able to plot charts that allowed me to observe gross profit or gross loss trends over a period of time. I was also able to observe profit to loss ratio of movies and how that ratio had declined over a period of time. I further examined profit to loss ratio by plotting them on a genre wise basis. Besides plotting graphs, I created tables that provided supporting information regarding the commerciality of movies. The investigation of this section wouldnt have been possible without the feature budget and gross. On the basis of these two features I was able compute gross profit and then futher compute average gross profit or gross loss. Using these to two feature I was also able to count the number of profitable and unprofitable films which further helped me to compute profit-loss ratios. These two features definitly strenghtened each other and made the investagtion for this section possible.
Were there any interesting or surprising interactions between features?
I think the most interesting interaction I observed in this section was between profit-loss ratio and title year. Plotting the profit-loss ratio of films against title year displayed how the profit ratio had declined over the year. I was indeed surprised by this investigation because it revealed how steeply the profit ratios had declined from 12:1 in 1983 to 0.76:1 in 2008.
Extras: Final Plots and Summary
Below are the three plots along with their brief descriptions that can provide an overview of the analysis:
Plot 1:
The distribution of scores
Description:
Distribution of imdb score appears to be normal, however score of 6.0 to 7.0 are skewing it slightly to the left.
Plot 2:
User votes and user reviews- the strongest correlated features.
Description:
An obvious postive correlation was observed between user votes and user reviews. With an r value of 0.77, it was apparently also the strongest correlation of the entire analysis.
Plot 3:
Profit-Los ratio of movies per year
Description:
I plotted this line graph to display the profit to loss ratio of movies per year. Dispite some missing values (because of undefined ratios), the graph was able to display the consistent decline in profit ratios from 1980 onwards.
Reflection
In its original form the imdb movie data set contained data on 5043 movies across 28 variables. After removing NA and duplicate values the data points were reduced to 3723 observations. I engineered 8 new features during the course of the project increasing the tally of features to 36 by the end. To progress in a systematic way, I divided the project into three parts. The first dealt with premilinary exploration of data through genres. In the second part, relationships and trends between variables were examined. And in the concluding part, I emphasised more on understanding the commercial side of movies.
During my investigation user reviews and user votes showed the strongest correlation between any two variables I had observed. Observing user rating, budget and gross figures with title year showed how ratings had declined over the years. While budget and gross figures showed how they had inclined over the year. I was hoping to see a positive relationship between user ratings and gross, however when I plotted a scatter plot to check their correlation, I found nothing between them. I struggled at that point to find a decent correlation between them. I tried tranforming ratings to log scale but it still didnt work.
In the concluding part of the analysis, I observed gross profit/loss and profit to loss ratio figures over time. Some surprising insights come to light during this analysis. I observed how the profit to loss ratio of movies had declined over the years yet the film industry kept making money.
I am thankful to chaunsun76 for creating this dataset and making it available for other to use. Even though it is a fantastic dataset, it can be further optimised and improved. Adding a feature like critic ratings and standardizing features budget and gross in one currency can make this dataset even more effective. Also I would like to see more number of movies released before the year 2000 added to the dataset. This will help in drawing better results when comparing movies with repect to the year they were released in. An imporved version of this dataset can be used to perform more comprehensive explorations and serious insight can be gained about the business of movies.
title: Understanding Movies author: Gautam Joshi date: ‘2017-10-12’ slug: understanding-movies categories: [Data Science, Exploratory Data Analysis] tags: [Movies, Data Science, imdb.com, kaggle.com] —